REINFORCE vs RLOO
For this chapter only, I’ll be using a simpler reward function: The reward is the number of words that start with “A” or “a”.
How is reinforcement learning different from supervised learning?
In supervised learning, we want to train the model
to accurately predict labels given inputs.
For instance, the input might be “the position of all the pieces
on a chess board”, and the label might be
“which side has the advantage, as estimated by a human judge”.
The dataset looks like a list of (input, label) tuples.
In reinforcement learning, we instead want to train the
model to produce good actions, as measured by some reward
function. The action might be “go play a chess game”,
and the reward would be “did you win?”
Typically there isn’t a fixed dataset of (action, reward) tuples,
since the model is taking the actions on the fly.
In my case, the action is “write a story with 100 tokens”, and the reward is “how many words started with A or a?”
The REINFORCE algorithm
If the model produces a story with a high reward, we want to nudge the model to generate stories more like that one.
Procedure:
- Feed the generated text to the model to get a probability, i.e. how likely the model thinks the text is
- Use backpropagation to get the
gradientof that probability with respect to the model weights. - If we add
gradientto the weights, we’ll make the model more likely to generate this text sequence, and in theory also more likely to generate similar text sequences. - We want to nudge the model more if the reward was higher (and vice versa),
so instead we add
reward * gradientto the weights.
This is the REINFORCE algorithm. (The REINFORCE paper has variants on this algorithm, so I’m simplifying.)
For convenience we use the cross-entropy loss to represent the model’s probability of seeing a text. Hence we have to be careful with the sign—if we want to increase the probability of a text sequence, we should add the gradient with the right sign so that the cross-entropy loss decreases.
PyTorch doesn’t have the best support for
directly adding gradients to a model’s weights
(although it can be done with some hacks).
It’s easier to instead use torch.optim.SGD as a middleman,
which has the same effect of adding a gradient to all model weights.
Let’s apply the REINFORCE algorithm on two identical trains (except for seed):
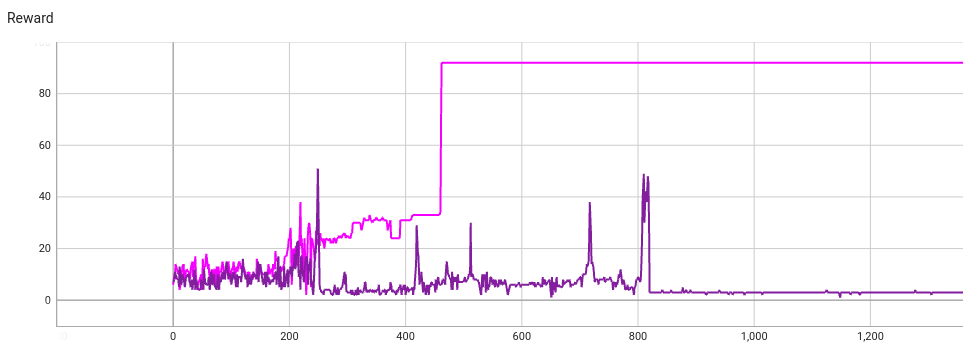
One of the models (pink) finds a high reward text. After step 462 the model predicts that text at every step:
Once upon a time in a big nation with a little a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a
The other train fixates on a different story, except this one has much lower reward:
Once upon a time, a big and the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the
What went wrong with the second train?
The RLOO algorithm
The problem is that the model gets stuck in a local optimum. If the model happens to generate the same text sequence multiple times, then REINFORCE will keep making that text sequence more likely, so the model will keep generating it. Hence the model will inevitably fixate on one particular text. And this text doesn’t have to be a high reward text, as seen above.
The solution is to normalize the reward, using recent rewards as a baseline. If the model generates a text sequence whose reward is higher than those of recent generations, that text sequence should get positive reward after normalization. We want the model to move in this direction.
Conversely, if a text sequence has a reward that’s lower than recent generations’ rewards, the normalized reward should be negative, even if the raw reward is still high. We want to decrease the probability that the model predicts worse-than-normal sequences.
This technique is known as REINFORCE-Leave-One-Out (RLOO—see Ahmadian et al. for more).
Here’s a plot of the reward over time of two RLOO runs (both green), versus the REINFORCE runs above:
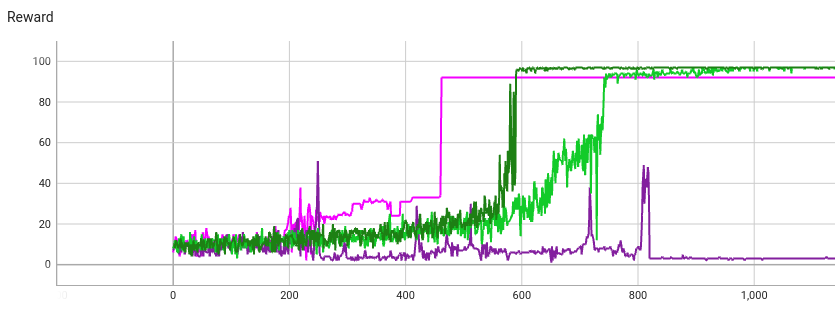
RLOO can take longer to find a high reward, since it has to generate multiple texts (in my case 10) to get an estimate of recent rewards. Hence it only takes 1 optimizer step per 10 generations. The x-axis is the number of text generations (what TensorBoard sees as steps).
But RLOO avoids getting stuck on a low-reward sequence, and its final reward is higher. This is because RLOO is “never satisfied”. If it gets mostly reward 92 but occasionally a reward of 93, RLOO will push the model weights towards reward 93 even though reward 92 is already very good (maximum possible is 97).
Thus the second RLOO run finds this sequence with the highest possible reward:
Once upon a time a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and a and