What is the KL penalty?
From now on, we’ll use the reward function that measures alliteration, as defined here.
Why do we even need the KL penalty?
We could just train a model as-is. If we do, the reward looks great:
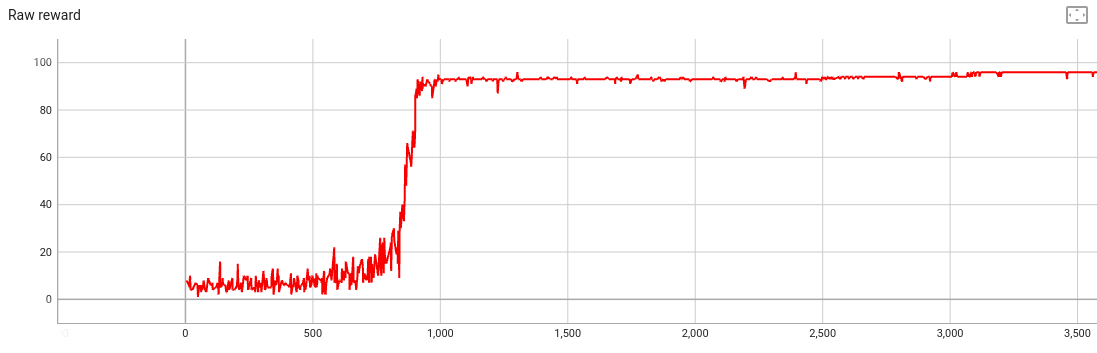
But if we look at the text generations near the end of training, the model always predicts the same 100 words:
Once upon a time to the tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall tall
Gradient descent has singlemindedly pushed the model weights toward maxmizing the reward function, and we’ve lost important qualities like:
- The model should generate a variety of texts, not the same one every time
- The text should be a story with acceptable grammar and coherence, not just unrelated words
Definition of the KL penalty
KL stands for Kullback–Leibler, as in Kullback–Leibler divergence. The KL divergence can be interpreted as a difference in cross-entropies, and we’ll use that form for the penalty:
kl_penalty_term = beta * (lm_cross_entropy - original_lm_cross_entropy)
where
beta >= 0is a hyperparameter controlling the penalty strengthlm_cross_entropyis the cross entropy loss of the language model on the current text generationoriginal_lm_cross_entropyis the cross entropy loss using a copy of the weights before reinforcement learning
We add the kl_penalty_term to raw_reward
(i.e. the reward from counting alliteration)
and then apply RLOO to that composite reward.
Motivation:
- Suppose that the LM has generated a sequence like “tall tall tall….” This sequence has high raw reward, but since this isn’t coherent English, we’d like the composite reward to be low.
lm_cross_entropywill be a small positive number, since the LM did generate this text.original_lm_cross_entropywill be a large positive number, since the original LM wouldn’t have generated this text.- Hence the
kl_penalty_termwill be negative, which will reduce the composite reward.